


【大模型系列】更像人类行为的爬虫框架
随着大规模模型技术的兴起,我们可以看到百模大战、各种智能体、百花齐放的应用场景,那么作为一名前端开发者,以前端的视角,我们应当如何积极做好技术储备,开拓技术视野,在智能体时代保持一定的竞争力呢?我尝试通过一系列文章来总结一下!
前言
可能很多人会好奇,你写爬虫就写爬虫为啥要和大模型扯上关系,明显的蹭热点吧。其实我们在做大模型应用时,比如问答系统、内容生成等应用时,通常会用到检索增强生成 (RAG) 技术,标准 RAG(以智能问答🌰) 流程图如下,大致分为以下几个步骤:

离线部分
- 知识库:数据从各种来源收集并存储在知识库中。
- 清洗、装载:数据进行预处理和清洗,以确保数据质量、清洗后的数据被装载为文档。
- 文档:将预处理后的数据组织成文档格式。
- 切分:将文档切分成更小的段(chunks),以便后续处理。
- 向量化:将切分后的文档段通过向量模型转换为向量表示。
- 向量数据库:向量化的文档段存储在向量数据库中,便于快速检索。
在线部分
- 用户请求:用户发出查询请求。
- Prompt: 用户的请求被处理为一个prompt,准备进行向量化。
- 向量化:用户请求的prompt通过向量模型转换为向量表示。
- 相似度查询:根据向量化的用户请求在向量数据库中进行相似度查询,检索相关的文档段。
- 提取相关知识:检索到的相关文档段作为背景知识注入到提示词模板中。
- 提示词模板:将检索到的背景知识与用户请求结合,生成完整的提示词。
- LLM(大型语言模型):使用提示词生成最终的回答或内容。
- 返回用户:最终的生成内容返回给用户。
我们可以看到,我们的回答是否准确,是否具备差异性,来源于我们的知识库内容的丰富程度和相关性。而知识库内容的获取途径,其中重要的组成部分就是爬虫。
关键概念
如果你以前了解过爬虫相关概念,在讲到爬虫的时候,脑子里蹦出来的会有以下关键词
- JS 渲染(JavaScript Rendering)
在现代网页中,很多内容是通过 JavaScript 动态加载和渲染的。这意味着传统的静态网页爬虫(如直接抓取 HTML 内容的爬虫)可能无法获取这些动态加载的内容。因此,爬虫需要具备执行 JavaScript 的能力,以便能够完全渲染页面并获取所有需要的数据。
- 无头浏览器(Headless Browsers)
无头浏览器是一种在没有图形用户界面的环境中运行的浏览器。这类浏览器能够执行 JavaScript,并可以模拟用户在浏览器中的操作,如点击、输入文本和滚动页面。常用的无头浏览器有 Puppeteer 和 Playwright,它们基于 Chrome 和 Firefox 等主流浏览器内核,提供了强大的网页自动化和爬取功能。
- 等待元素渲染(Waiting for Elements to Render)
由于网页内容可能是动态加载的,爬虫在抓取页面内容时需要等待特定元素加载完成。无头浏览器通常提供了等待元素出现的方法(如 waitForSelector),以确保页面完全加载后再进行数据提取。这样可以避免抓取到不完整的内容或空白页面。
- 代理服务器(Proxy Server)
为了防止被目标网站封禁和提高爬取效率,爬虫通常会使用代理服务器。代理服务器可以隐藏爬虫的真实 IP 地址,并通过轮换多个代理 IP 来模拟不同的访问来源,避免爬取行为被检测到并封禁。使用代理服务器还能绕过地理限制,访问特定区域的网站内容。
接下来我给大家介绍一个爬虫框架,并实现一个简单的例子,让大家了解下这个框架。
功能介绍
Crawlee 是一个高效的网页爬虫和抓取工具,旨在帮助开发者快速构建可靠的爬虫系统。它兼具HTTP请求和无头浏览器的爬取能力,适用于各种动态和静态网页内容的抓取。包含 node 和 python两个版本

🌈 主要功能
- HTTP和无头浏览器爬取:支持传统的HTTP请求和现代无头浏览器(如Playwright和Puppeteer),可以抓取动态生成的内容。
- 持久化队列:自动管理和持久化URL队列,确保高效和可靠的抓取过程。(广度优先和深度优先)
- 自动扩展:支持根据需求动态调整爬取规模,提高抓取效率。
- 代理轮换:内置代理轮换功能,避免IP被封,提高爬取的稳定性。
- 生命周期管理:提供灵活的生命周期管理,允许自定义爬虫的各个阶段。
- 错误处理和重试机制:自动处理爬取过程中遇到的错误,并进行重试,确保数据完整性。
👍 优势
- 单一接口:统一的接口处理HTTP和浏览器爬取,简化开发过程,减少学习成本。
- JavaScript渲染支持:通过无头浏览器渲染页面,抓取动态内容,使得爬取结果更完整。
- 丰富的配置选项:提供多种配置选项,适应不同的爬取需求,增强灵活性。http2、浏览器请求他、fingerprints
- TypeScript编写:利用TypeScript的强类型检查和自动补全功能,提高代码质量和开发效率。
- 内置快速HTML解析器,如Cheerio和JSDOM
- CLI和Docker支持:提供命令行工具和Docker支持,方便集成和部署,适应不同的开发环境。
🆚 与其他爬虫框架对比
- Scrapy:Scrapy 是一个强大的传统HTTP爬取框架,但不支持动态内容的抓取。Crawlee 在处理动态内容方面更有优势,特别是对现代Web应用的抓取。
- BeautifulSoup:BeautifulSoup 主要用于解析HTML,功能相对简单,不具备Crawlee 的自动扩展、代理轮换和生命周期管理等高级功能。
- Selenium:Selenium 可以抓取动态内容,但缺少持久化队列和自动扩展功能,且性能相对较低。Crawlee 提供了更高效和集成的解决方案。
Crawlee 主打一个高效、可高、速度极快,接下来我们通过一个 demo,来了解它有哪些功能!
Live Demo
目标:挑战 20 分钟,完成掘金前端话题内容的爬取,并完成结构化存储
⚠️注意以下示例代码,大部分都是 github 的 copilot 帮我补全的,我只提供思路,他就帮我写完了!!!
初始化项目
打开一个终端,执行以下命令
crawlee 提供 3 个类,方便用户针对不同场景选择不同的类
CheerioCrawler主要针对普通 http 的爬取,并通过 cheerio 库来解释 html,快速高效,但无法处理 js 渲染PuppeteerCrawlergoogle 开源的无头浏览器Puppeteer,提供标准 API 来控制 Chrome/FirefoxPlaywrightCrawlermicrosoft 开源的无头浏览器**playwright** ,提供标准 API 来控制 Chrome/Firefox、Webkit 等浏览器,功能更加齐全
由于笔者原来一直使用 puppeteer,以下会使用 PuppeteerCrawler 来完成 demo,其中 cheerio 可以理解为 node 版本的 jQuery,提供强大 dom 操作
# 你也可以通过以下命令,通过官方模版初始化应用
# npx crawlee create juejin-crawler
cd juejin-crawler
npm init
npm install --save crawlee cheerio puppeteer
安装依赖、启动脚本
打开 package.json修改以下内容,关键两个改动
- 为了简单,我们是用 esm 来解析 js 文件,需增加
"type": "module", - 增加一个启动脚本
"start": "rm -rf storage/ && node src/main.mjs",其中 main 文件在后续创建
{
"name": "juejin-crawler",
"version": "1.0.0",
"main": "index.js",
"scripts": {
"start": "rm -rf storage/ && node src/main.mjs",
"test": "echo \"Error: no test specified\" && exit 1"
},
"type": "module",
"author": "",
"license": "ISC",
"description": "",
"dependencies": {
"cheerio": "^1.0.0-rc.12",
"crawlee": "^3.11.1",
"puppeteer": "^22.15.0"
}
}
增加入口文件
增加一个入口文件 src/main.mjs
- 需要引入一个 router 文件,用来处理整体 handler 操作,包括如何处理列表页、如何处理详情页等等
- 需要引入一个 config 文件,主要用来配置结构化数据所需的配置,比如爬取页面 URL、页面对于的选择器,如 title 对应详情页的
article-title - 初始化一个PuppeteerCrawler实例,具体配置作用,见代码
- 把请求入口链接加到队列,并启动任务
main.mjs 整体内容如下
import { PuppeteerCrawler, ProxyConfiguration, log } from 'crawlee';
import { router } from './routes.mjs';
import config from './config.mjs';
log.setLevel(log.LEVELS.DEBUG);
log.debug('Setting up crawler.');
// const proxyConfiguration = new ProxyConfiguration({
// proxyUrls: [],
// });
// 创建 PuppeteerCrawler 实例
const crawler = new PuppeteerCrawler({
// 是否使用会话池,启用后爬虫会重用会话和 Cookie
// useSessionPool: true,
// 是否为每个会话持久化 Cookie,启用后每个会话会有自己的 Cookie 存储
// persistCookiesPerSession: true,
// 代理配置,用于通过代理服务器发送请求,可以用于绕过 IP 限制或地理位置限制
// proxyConfiguration,
// 最大并发请求数,控制同时进行的请求数量
maxConcurrency: 10,
// 每分钟最大请求数,控制每分钟发送的请求数量
maxRequestsPerMinute: 20,
// 启动上下文配置
launchContext: {
launchOptions: {
// 是否以无头模式启动浏览器(无头模式:没有图形界面),设置为 false 表示有图形界面
headless: false,
},
},
// 爬虫运行时的最大请求数量,当达到这个数量时,爬虫会停止
maxRequestsPerCrawl: 1000,
// requestHandler 定义了爬虫在访问每个页面时要做的操作
// 可以在这里提取数据、处理数据、保存数据、调用 API 等
requestHandler: router,
// 处理请求失败的情况,记录失败的请求并输出错误日志
failedRequestHandler({ request, log }) {
log.error(`Request ${request.url} failed too many times.`);
},
});
// 添加要爬取的请求,config 是一个包含 URL 和标签的数组
// 这里将每个 item 的 url 和 label 添加到爬虫的请求队列中
await crawler.addRequests(config.map(item => { return { url: item.url, label: item.label } }));
// 启动爬虫
await crawler.run();
增加配置文件,增加灵活性
增加一个配置文件 src/config.mjs ,具体实现以下功能
- 配置要爬取的页面 URL,给定一个标签,如
juejin - 配置各个字段的选择器,这个对于前端工程师来说,小菜一碟,截图看看例子
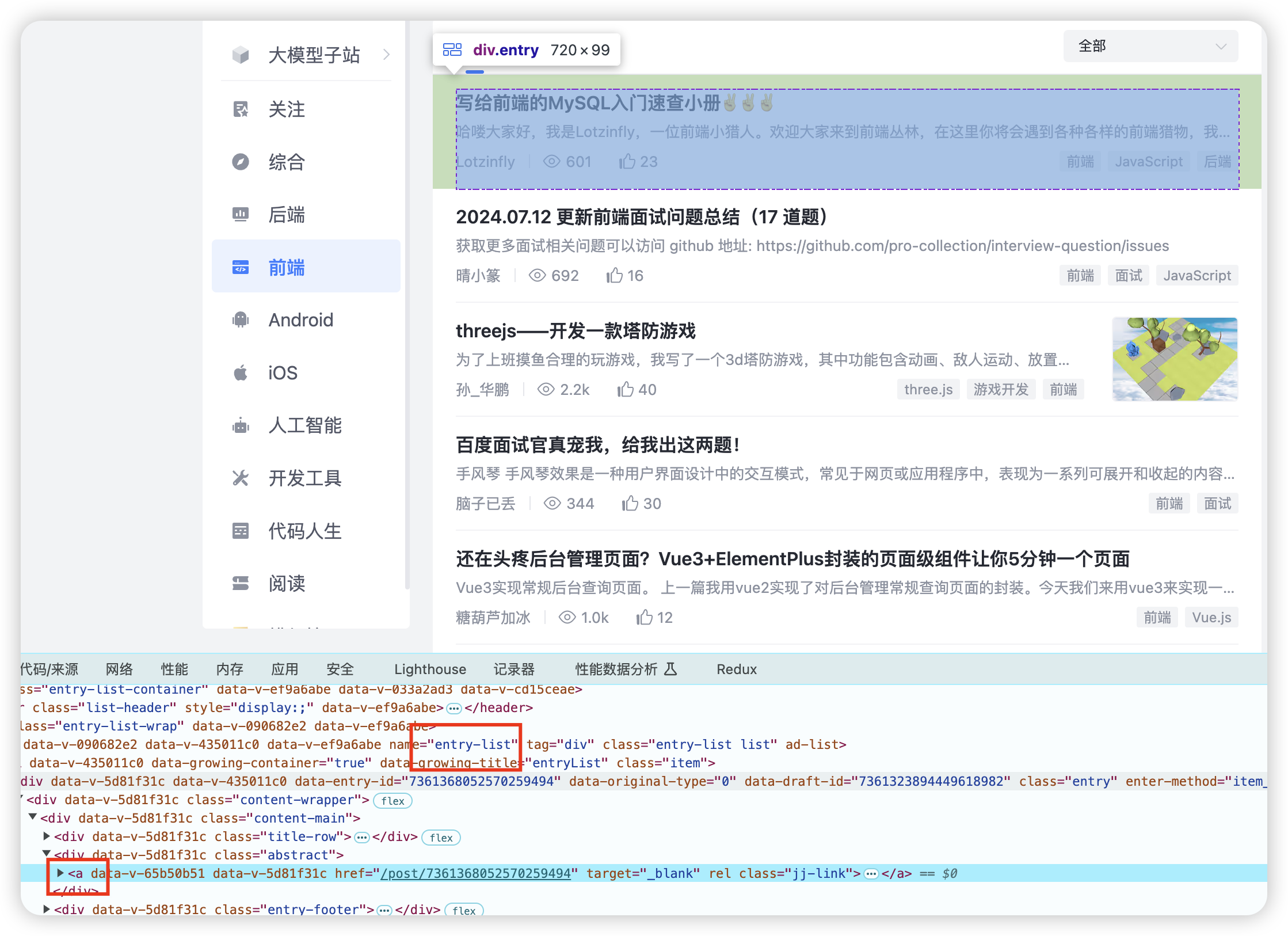
具体配置信息如下:
export default [
{
label: 'juejin',
url: 'https://juejin.cn/frontend',
selector: {
detail: '.entry-list .title-row a',
title: 'h1.article-title',
author: '.author-info-box .author-name a span',
modifiedDate: '.author-info-box .meta-box time',
hit: '.author-info-box .meta-box .views-count',
readTime: '.author-info-box .meta-box .read-time',
description: '.article-header p',
content: '.article-viewer',
},
}
]
增加处理逻辑
增加真正处理逻辑文件 src/routes 这里增加两个处理逻辑,列表页和详情页
- 列表页:通过模拟滚动的方式,触发滚动底部加载更多,并把列表页所有文章加入爬取队列
- 详情页:通过配置的选择器,把详情页的数据结构化,并存储到数据集
- 如果这里为了实现知识库相关功能,也可以把拿到的数据存储到向量数据库,这里不做演示
import { createPuppeteerRouter, Dataset } from 'crawlee';
// import { Article } from './db.mjs';
export const router = createPuppeteerRouter();
import config from './config.mjs';
config.map(async item => {
const dataset = await Dataset.open(item.label);
// 打开列表页操作
router.addHandler(`${item.label}`, async ({ request, page, enqueueLinks, log }) => {
page.setDefaultTimeout(5000);
log.debug(`Enqueueing pagination: ${request.url}`)
// 由于掘金是滚动加载,这里通过模拟滚动到底部,实现页面切换
const scrollToBottom = async (page, scrollDelay = 5000) => {
let previousHeight;
let newHeight;
let reachedEnd = false;
let count = 0;
// 这里只滚动2次,如果还没有到底部,可以根据实际情况调整
while (!reachedEnd && count < 2) {
previousHeight = await page.evaluate('document.body.scrollHeight');
await page.evaluate(`window.scrollBy(0, ${previousHeight})`);
await new Promise(resolve => setTimeout(resolve, scrollDelay));
newHeight = await page.evaluate('document.body.scrollHeight');
count++;
if (previousHeight === newHeight) {
reachedEnd = true;
}
}
};
// 模拟滚动加载
await scrollToBottom(page);
// 等待页面加载完成,这里只为演示,在这个例子中,不需要等待
await page.waitForSelector(item.selector.detail);
// 把列表页的详情页链接加入到爬虫队列中
await enqueueLinks({
selector: item.selector.detail,
label: `${item.label}-DETAIL`,
});
await page.close();
});
// 打开详情页操作
router.addHandler(`${item.label}-DETAIL`, async ({ request, page, log }) => {
page.setDefaultTimeout(5000);
log.debug(`Extracting data: ${request.url}`)
const urlParts = request.url.split('/').slice(-2);
const url = request.url;
await page.waitForSelector(item.selector.content);
const details = await page.evaluate((url, urlParts, item) => {
return {
url,
uniqueIdentifier: urlParts.join('/'),
type: urlParts[0],
title: document.querySelector(item.selector.title).innerText,
author: document.querySelector(item.selector.author).innerText,
modifiedDate: document.querySelector(item.selector.modifiedDate).innerText,
hit: document.querySelector(item.selector.hit).innerText,
readTime: document.querySelector(item.selector.readTime).innerText,
content: document.querySelector(item.selector.content).innerText,
contentHTML: document.querySelector(item.selector.content).innerHTML,
};
}, url, urlParts, item);
log.debug(`Saving data: ${request.url}`)
// await Article.create(details);
await dataset.pushData(details);
await page.close();
});
});
router.addDefaultHandler(async ({ request, page, enqueueLinks, log }) => {
log.error(`Unhandled request: ${request.url}`);
});
启动爬虫
npm start

打开 chrome 浏览器,按照逻辑自动打开列表页、详情页

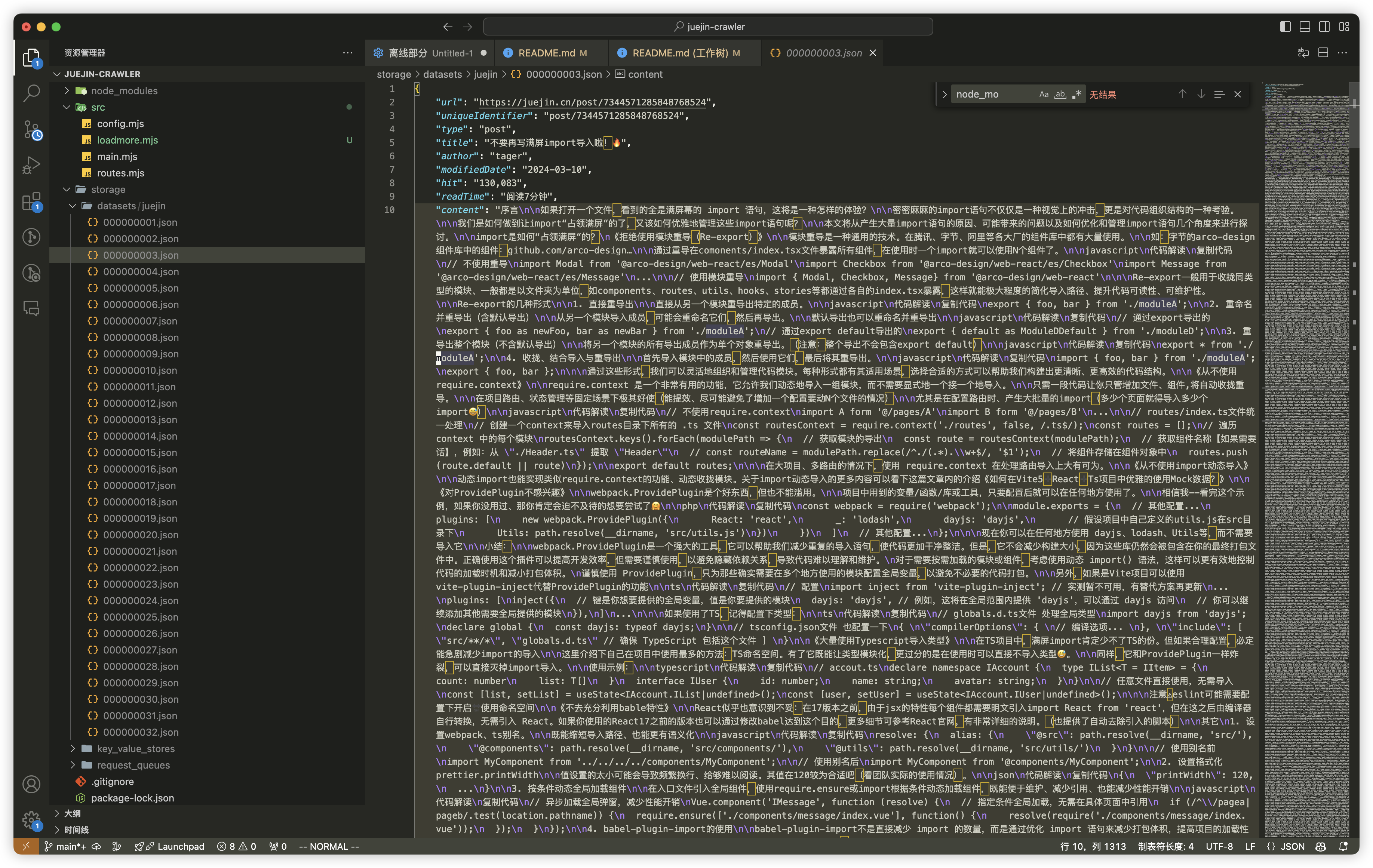
数据存储到 storage 目录下,并按照我们定义的结构,以 json 格式保存起来
增加代理 IP Server
由于上面的例子我做了限制,如果爬取并发数太高的话,大概率会被封禁,所以这个时候就需要用到代理 ip 服务 和 session 管理
- Proxy 管理:如果有代理 URL,只需以下几行代码,即可实现代理访问,并通过 proxyInfo 方法检查当前代理
import { PuppeteerCrawler, ProxyConfiguration } from 'crawlee';
const proxyConfiguration = new ProxyConfiguration({
proxyUrls: ['http://proxy-1.com', 'http://proxy-2.com'],
});
const crawler = new PuppeteerCrawler({
useSessionPool: true,
persistCookiesPerSession: true,
proxyConfiguration,
async requestHandler({ proxyInfo }) {
console.log(proxyInfo);
},
});
- session 管理:使用 session 管理,主要为了过滤掉被阻止或者不工作的代理,大致代码如下:
import { PuppeteerCrawler, ProxyConfiguration } from 'crawlee';
const proxyConfiguration = new ProxyConfiguration({
/* opts */
});
const crawler = new PuppeteerCrawler({
// To use the proxy IP session rotation logic, you must turn the proxy usage on.
proxyConfiguration,
// Activates the Session pool (default is true).
useSessionPool: true,
// Overrides default Session pool configuration
sessionPoolOptions: { maxPoolSize: 100 },
// Set to true if you want the crawler to save cookies per session,
// and set the cookies to page before navigation automatically (default is true).
persistCookiesPerSession: true,
async requestHandler({ page, session }) {
const title = await page.title();
if (title === 'Blocked') {
session.retire();
} else if (title === 'Not sure if blocked, might also be a connection error') {
session.markBad();
} else {
// session.markGood() - this step is done automatically in PuppeteerCrawler.
}
},
});
如果你业务中需要代理服务,可以通过快代理购买服务,简单易用,所以推荐

⚠️⚠️⚠️ 本文内容,包含示例代码,部分由 AI 生成!!
以上示例代码均提交到 juejin-crawler 欢迎👏👏👏 star 、点赞👍、关注、讨论
至此,第一篇关于 AIGC 文章已完成,预告下下一篇文章,关于大模型 LangchainJS 工具的介绍,期待(✧∀✧)